 Michael Crown
Michael Crown
data scientist
Weekly Sales Forecasts Using Non-Seasonal ARIMA Models
Examining a Method to Reduce the Number of Models Required for Many Time Series
Executive Summary
This report summarizes the process and results of creating one year of department-wise sales forecasts for 45 Walmart stores (over 3,000 individual departments). Because of the large number of time series, forecasts were created using inter-store department averages and transforming results to estimate store-specific department sales.
Analysis: Autoregressive Integrated Moving Average (ARIMA) modeling was used to create one year of weekly forecasts using 2.75 years of sales data, with features for store, department, date, weekly sales, and if the week contains a major holiday. The latter was used as an exogenous variable. Performance was measured using normalized root-mean-square error (NRMSE)
Results and Conclusions: The 75th percentile NRMSE for department-average forecasts was 0.092, and the 75th percentile NRMSE for individual department forecasts was 0.155. In other words, 75 percent of the department-wise forecasts had an average error that was less than 15.5% of the mean sales during that time. While the method used worked well for most individual departments, some had NRMSE > 0.5.
While it requires more computational resources, it would likely be more effective to model every department within each store individually, which would require 3,331 models for the departments in this set. That said, there are other possibilities for improving results, such as modeling a dataset that contains at least four or five years of sales data.
Limitations:The primary limitation is this projects was the size of the dataset: the entire set consists of only 143 weeks (2.75 years) of data, which prohibited modeling any seasonal component that might exist. There was also missing sales data for some departments.
INTRODUCTION
Sales forecasting is an important component of modern business, as it helps decision makers anticipate fluctuations in sales that could be costly if missed. Changes in sales can arise from long-term trends, seasonal and non-seasonal effects, external factors like holidays or weather (exogenous variables), and there are also random fluctuations. ARIMA is a popular method of modeling time series, because of it’s flexibility and generalizability.
The primary goal of this project was to examine a method to use fewer than 100 non-seasonal ARIMA models to generate weekly forecasts for over 3000 individual series, over the span of one year. The forecasts were generated by simulating the passage of time and updating the models each week from left out data. That is not be confused with producing iterative projections by updating using previous predictions.
QUESTIONS
Two questions were posed at the start of this project:
- How well can weekly sales be forecast using an averaging method?
- Is modeling averages by department or store more likely to produce superior results?
DATA
The dataset used in this project contained five features:
- Store: integer values to identify individual stores.
- Dept: integer values to identify specific departments (not unique per store).
- Date: strings of the form yyyy-mm-dd, meant to indicate the week of month and year.
- Weekly_Sales: floats giving the sales recorded for that week, in dollars.
- IsHoliday: Boolean (True/False) for if a major holiday occurred during that week.
| Store | Dept | Date | Weekly_Sales | IsHoliday | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 2010-02-05 | 24924.50 | False |
| 1 | 1 | 1 | 2010-02-12 | 46039.49 | True |
| 2 | 1 | 1 | 2010-02-19 | 41595.55 | False |
ANALYSIS
Preprocessing
Separate IsHoliday
IsHoliday was placed in a separate data frame, with the unique Date values as the index. The strings representing dates were converted to actual date-time values. The resulting frame contained 143 rows, one for each week in the set. This data frame will be referred to as is_holiday.
Create sales Data Frame
The data frame containing the remaining features was restructured into a more useful form. Specifically, the data frame was grouped by Date, Store and Dept, using mean as the aggregate function. In this case, using an aggregate function did not affect the values, because that grouping left only one value per unique triple. As with is_holida, the Date strings were converted to date-time values. Unstacking the Store and Dept levels left the final sales data:
| Store | 1 | ... | 45 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dept | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 87 | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 |
| Date | |||||||||||||||||||||
| 2010-02-05 00:00:00 | 24924.50 | 50605.27 | 13740.12 | 39954.04 | 32229.38 | 5749.03 | 21084.08 | 40129.01 | 16930.99 | 30721.50 | ... | 8818.12 | 32016.42 | 22708.11 | 68203.08 | 4002.34 | NaN | 63833.63 | NaN | 8393.22 | 347.23 |
| 2010-02-12 00:00:00 | 46039.49 | 44682.74 | 10887.84 | 35351.21 | 29620.81 | 9135.00 | 18310.31 | 37334.83 | 16562.49 | 31494.77 | ... | 5895.61 | 19724.40 | 13860.64 | 44898.91 | 2665.98 | 2.94 | 41131.42 | NaN | 5011.36 | 553.25 |
To help ensure successful modeling, columns with more than 10% of their values missing were dropped, and those with less than this cutoff had missing values forward filled, then backward filled to fill all missing values.
Averaging
The sales data was used to create two data frames central to the modeling: store_avg and dept_avg. These two frames contained sales averaged within individual stores, and cross-store averages by department number, respectively. The former thus had columns indicating only unique store numbers, and the latter only unique department numbers.
A final step of preprocessing was to necessarily held off until the first portion of exploratory analysis could be conducted, and so it will be mentioned in the next section.
Exploratory Analysis
Check for Minimal Scale Differences
Because the method of modeling depends on estimating department-specific sales from averaged sales, it was important to minimize scale differences between individual series and these averages: For an individual series with values substantially smaller than the averaged forecast from which it is estimated, relatively small errors in the forecast will be exaggerated for the individual. Thus, the store_avg and dept_avg sets were analyzed to determine which had the smallest overall scale differences when compared to the individual series. This was done by computing the ratios of original and averaged series, and comparing their distributions.
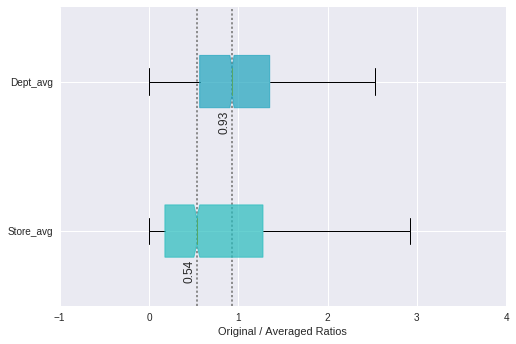
The box plots show that dept_avg was the ideal set for the method tested, and so was chosen over store_avg going forward. This leads to the final portion of preprocssing that was skipped in the last section: A set called mean_diffs was created using
\begin{equation} \Delta_d = S_d - D_d, \end{equation}where Δ, S, and D are the matrix representations of mean_diffs, sales, and dept_avg, respectively. The subscript d represents performing operations on matching department numbers through broadcasting, rather than column-wise operations. It is this new set that will be used to compute estimates from forecasts of averages.
Tests for Stationarity
Because time series modeling depends on stationarity, initial steps to ARIMA modeling typically include plotting the autocorrelation function (ACF) and partial-autocorrelation function (PACF) of the series to be modeled, seasonal decomposition, and tests for stationarity. The ACF and PACF help to determine how stationary a series is and what terms to use in fitting the model. Seasonal decomposition separates the series into three components: trend, seasonal, and what remains (residual), for the purpose of understanding the structure of the series. The test of stationarity in this project was the Dickey-Fuller test.
Because there were so many models to be fitted in this project (and because most of the series have similar structures), the above steps were taken on one representative series. The results of this step were not used to determine the terms to use in every model, rather they were used to gain some insight into the overall structures.


The Dickey-Fuller tests for stationarity were performed on the original series, as well as after taking first and second differences. The resulting p-values are tabulated below.
| Difference: | None | First | Second |
|---|---|---|---|
| p-val | 0.1731 | 0.0047 | 0.0000 |
Modeling
ARIMA models require order values (p, d, q) to be set, which correspond to autoregressive terms, nonseasonal differences, and lagged forecast errors. These values can be determined using the methods mentioned at the end of the last section, but because this project involves so many models, selecting and evaluating the order for each by hand would be a lengthy process. To that end, it was necessary to automate the selection process for each model, as described in the following paragraph.
Automated selection was achieved by iterating over each series, and fitting each to all order combinations, with values from zero to two. The models were evaluated, and orders selected, using Akaike Information Criterion (AIC): the order that produced the smallest value for a given model was selected. Error handling was necessary for this process, particularly for the event of maximum likelihood failing to converge with a particular order.
To check that values were being selected with some success, one of the original series was overlaid with in-sample predictions:
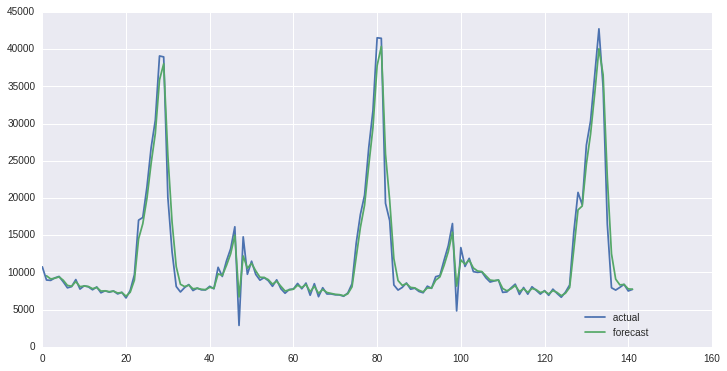
As can be seen, at least with this series, the selection process was successful.
Final Models
In order to achieve the goal of this project, the final part of the modeling process was to simulate the passing of time and update the models (i.e. re-fit with new orders). With each new set of updates, sales forecasts for all series were made and recorded, along with standard error and the lower/upper bounds of 95% confidence intervals.
Because holidays tend to fall on either different days of the week each year (e.g. Christmas), or different dates (e.g. Thanksgiving), the week of a holiday month where the peak sales fall might not fall in the same week as the holiday. Because of this, using is_holiday as an exogenous variable can cause some problems with the forecasts. With this in mind, a one week shift in the forecasts for this particular date range was found to produce the best results. A more complex method of shifting sales around to match individual holidays could be devised, but was unnecessary for this project.
Final Forecasts
The department-wise forecasts (store specific) were computed using
\begin{equation} \hat{S}_d = \hat{D}_d + \Delta_d, \end{equation}where the "hat" accents indicate forecast values, and the subscripts have the same meaning as in Eq. 1. This resulted in a data frame with the same structure as sales.
Evaluation
To evaluate the performance of the forecasts, the NRMSE was computed for both the initial department-average forecasts and the final forecasts. NRMSE was computed on the forecast range as follows:
\begin{equation} NRMSE = \frac{RMSE_d}{|\bar{D}_d|}, \end{equation}where RMSE is the common root mean square error, and the denominator is the absolute values of series means from dept_avg.
The NRMSE values were plotted as the heat maps in the figures below, and descriptive statistics tabulated:

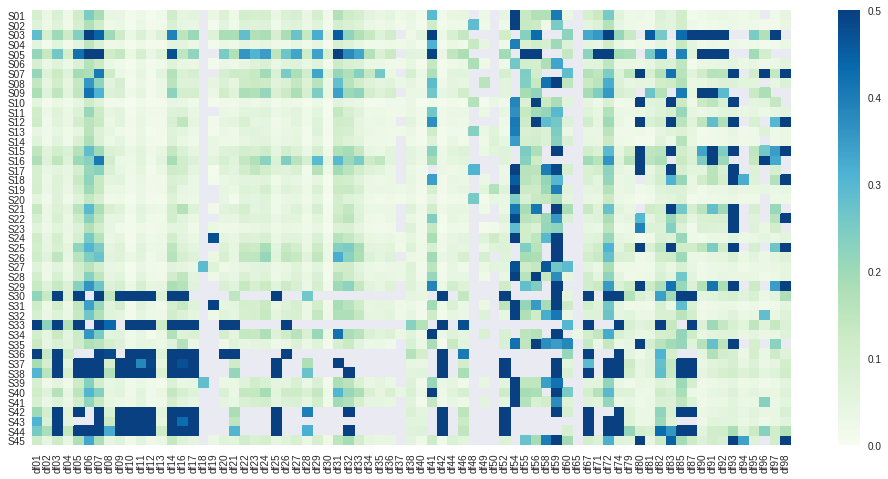
| mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|
| Dept_Avg | 0.083 | 0.069 | 0.015 | 0.040 | 0.055 | 0.092 | 0.352 |
| Dept_Ind | 0.618 | 6.345 | 0.007 | 0.039 | 0.070 | 0.156 | 208.302 |
RESULTS
Sales forecasts for department-average sales were overall quite accurate, with the median NRMSE being 0.055, which can be interpreted as forecast errors being within 5.5% of the sales means. The estimation of store-specific department sales resulted in a median NRMSE of approximately 0.070. Even with relatively low overall error, there are still some individual forecasts that have unacceptably high error. A pair of plots below show a selection of good and bad forecasts overlaid with the actual sales:
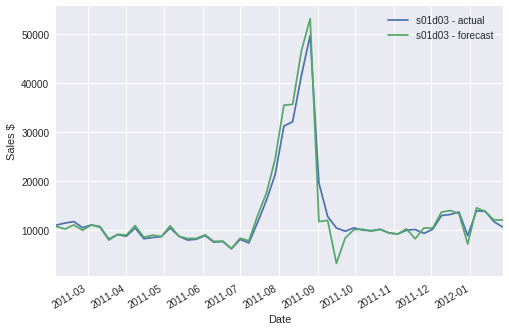
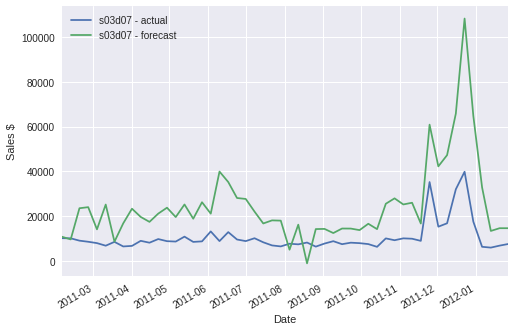
CONCLULSIONS
The method outlined in this project, used to significantly reduce the number of models required to make individual forecasts, was able to produce results with reasonably low error, though it is clear that some departments within specific stores should be modeled separately.
LIMITATIONS
The primary limitation in this project was the size of the dataset: the entire set consists of only 143 weeks (2.75 years) of data, which prohibited modeling any seasonal component that might exist. Additionally, there was missing sales data for some departments. Only one exogenous variable was used in modeling, which could limit forecasting potential; weather and unemployment data (available in a complementary set), might have improved the accuracy of forecasts.